 第11章 问答 重生2012:全球科技财阀
第11章 问答 重生2012:全球科技财阀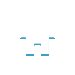 第11章 问答 重生2012:全球科技财阀
第11章 问答 重生2012:全球科技财阀军训结束后的第一周,姚班正式开始上课。
陈阳利用重生者的优势,在课堂上游刃有余。
数学分析课上精准回答了关於函数连续性证明的问题,计算机视觉课上提出用深度学习做特徵提取的思路,算法课上对动態规划的理解让老师连连点头。
就连下课后,陈阳也经常主动去老师办公室请教问题。
一周下来,姚班的几位核心教授都对这个大一新生留下了深刻印象。
周五下午是姚教授的《计算理论》课。
这是姚班最受重视的课程之一,姚教授每周只讲一次,但每次都是精华。
教室里坐得满满当当,大家都很认真。
姚教授今天讲的是计算复杂性理论,讲到p问题和np问题的关係时,他停下来,看著台下的学生。
“我有一个问题,“
姚教授的声音不大,但很有穿透力,
“假设我们有一个算法,能在多项式时间內验证某个问题的解是否正確,那么我们能不能在多项式时间內找到这个解?“
这是一个经典的思考题,涉及p=np这个千禧年七大数学难题之一。
教室里安静了几秒,大家都在思考。
陈阳举起手。
姚教授微微点头:“请讲。“
“目前来说,我们不能。“
陈阳站起来,“验证一个解的正確性,和找到这个解,是两个不同复杂度的问题。
比如数独游戏,验证一个填好的数独是否正確很容易,但要找到正確的填法,可能需要尝试大量组合。这就是np问题的特点——验证容易,求解难。“
姚教授眼中闪过一丝讚许:“继续。“
陈阳顿了顿,“但是,在某些特殊情况下,我们可以通过启发式算法或者近似算法,在可接受的时间內找到足够好的解。虽然不一定是最优解,但在实际应用中往往已经够用了。“
“很好。“姚教授点点头,
“理论和实践的结合,这是一个很重要的视角。这位同学叫什么名字?“
“陈阳。“
“陈阳同学的回答很有深度。
“姚教授对全班说,“大家要记住,学习计算理论不是为了证明数学定理,而是为了理解计算的本质,从而在实践中做出更好的设计。“
下课后,陈阳收拾东西准备离开。
“陈阳。“
姚教授站在讲台上,朝他招手。
“你刚才提到的启发式算法,“
姚教授看著他,“在什么样的实际场景中用过?“
陈阳知道,机会来了。
“我暑假的时候创办了一个爬虫公司,做数据分析。“
陈阳说,“在爬取数据的过程中,遇到了一个很棘手的问题,验证码识別。“
“验证码?“姚教授来了兴趣。
“对。传统的图像处理方法效果很不稳定,“
陈阳说,“所以我开始研究深度学习的方法来解决这个问题。“
“深度学习?“姚教授眼中的讚许更明显了,“这个方向很前沿。你遇到什么困难了吗?“
“遇到了。“陈阳组织著语言,“当我把网络层数加深的时候,出现了梯度消失的问题。反向传播到浅层的时候,梯度已经接近零了,导致浅层根本训练不动。“
姚教授点点头,这是深度学习领域人尽皆知的难题。
“我查阅了很多文献,“
陈阳说,“geoffrey hinton的预训练方法、yann lecun的卷积神经网络,都给了我很多启发。我尝试用relu激活函数代替sigmoid,用dropout防止过擬合,用数据增强扩充训练集。这些方法確实有效。“
“效果怎么样?“
“梯度消失的问题基本解决了。“
陈阳说,“但隨之而来的,出现了一个新的问题。“
“什么问题?“姚教授明显更感兴趣了。
“退化问题。“陈阳说,“当我把网络层数从8层增加到20层的时候,理论上模型的表达能力更强了,但实际训练出来的准確率反而下降了。而且这不是过擬合,因为训练集上的准確率也下降了。“
姚教授沉思了几秒:“这很有意思。你確定不是训练方法的问题?“
“確定。“
陈阳说,“我用完全相同的训练参数,8层网络能达到95%的准確率,但20层网络只有91%。这说明深层网络並没有学到更好的特徵,反而退化了。“
“你怎么解释这个现象?“
“我觉得,“陈阳说,“问题在於网络太深之后,优化变得非常困难。即使梯度能传回来,但优化路径太长太复杂,很容易陷入次优解。“
“有道理。“姚教授点点头,“那你是怎么解决的?“
陈阳深吸一口气,这是关键时刻。
“我尝试了一个想法,“他说,“改变网络的连接方式。“
“怎么改?“
“我在深层和浅层之间加了一些跳跃连接,“陈阳解释道,“让浅层的信息可以直接绕过中间层,传递到深层。这样深层网络在最坏的情况下,也能退化成浅层网络的效果,不会比浅层网络差。“
姚教授的眼睛亮了:“这个思路很新颖。具体是怎么实现的?“
“简单来说,就是让每一层学习的不是目標函数本身,而是目標函数和输入之间的残差。“陈阳说,“这样即使某些层学不到东西,也不会影响整体效果。“
“残差学习。“姚教授若有所思,“这个想法很有创造性。效果怎么样?“
“效果很好。“陈阳说,“用了这个方法后,我训练了一个18层的网络,准確率达到了98.5%,远远超过了浅层网络。而且训练速度也比之前快了很多。“
姚教授看著陈阳,沉默了几秒。
“陈阳,“他说,“你现在有时间吗?跟我去办公室,我们详细聊聊。“
“有。“陈阳说。
姚教授的办公室在fit楼五层,很宽敞,书架上摆满了书籍和论文。
“坐。“姚教授指了指沙发,然后给陈阳倒了杯茶。
“你刚才说的残差学习,“姚教授坐下来,“能画个图给我看看吗?“
“可以。“陈阳走到白板前,拿起马克笔。
他在白板上画了一个简单的网络结构图。
“传统的网络,“陈阳指著图说,“是让这些层去学习一个映射函数h(x),直接从输入x映射到输出y。“
“但在残差网络里,“他继续说,“我们让这些层去学习f(x)= h(x)- x,也就是输出和输入之间的残差。然后把x通过跳跃连接直接加到输出上,得到最终的y = f(x)+ x。“
姚教授盯著白板,眼神专註:“为什么这样做会更容易优化?“
“因为对於恆等映射来说,“陈阳说,“让f(x)学习为0,比让h(x)学习为x要容易得多。而在深层网络中,很多层確实应该接近恆等映射,这样才不会破坏浅层学到的特徵。“
“妙啊。“姚教授讚嘆道,“这个想法非常优雅。你是怎么想到的?“
陈阳早就准备好了说辞:“我在研究highway networks的一些早期思想时得到的启发。他们用门控机制来控制信息流动,但我觉得太复杂了。后来我想,能不能用最简单的加法连接?试了一下,发现效果特別好。“
本章未完,点击下一页继续阅读。(1 / 2)